SUMMARY
I tackle 1BRC in Fortran which requires processing 1B rows of weather station data (~15GB) to obtain min/max/mean for each station as quickly, as you can muster. I started out with a time of 2m8s and reduced it to a best run time of <6s on a 4 i7 laptop with 16GB RAM. I herein document how.
INTRODUCTION
The 1BRC data looks like this:
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
Bridgetown;26.9
Istanbul;6.2
Roseau;34.4
Conakry;31.2
Istanbul;23.0We need to calculate the min, max and mean for each place, given a file containing 1 billion rows. There are other details to the challenge but that’s the crux of it for me.
The original challenge is Java oriented, the best entry scored around 1.5s on a bare metal Hetzner AX161 (32 core AMD EPYC™ 7502P (Zen2), 128 GB RAM), utilising 8 cores. Since then, aficionados from many languages have accepted the challenge and produced some amazing code. The best C version heavily uses SIMD and completes in 0.15s: unbelievable!
Writing performant code turns out to be harder than it may seem because the little things add up when you do them a billion times. I started out by writing 12 LoC AWK program to get a sense of the challenge: it completes in about 6m21s. I then moved onto Haskell – my language du jour – to blow AWK out of the water. I wanted to keep the code pure and immutable, and that given, the best I could do in Haskell was 7m18s! Others in the Haskell community have produced much more performant implementations by using the monad escape hatch into a mutable and imperative style, but that defies the point of Haskell for me. My Haskell version was an order of magnitude away from what I’d consider reasonably better than AWK, so I decided to look elsewhere in attempt of my own fast implementation from first principles.
WHY FORTRAN?
Fortran landed on my radar forever ago when I realised that it was the implementation language for high performance linear algebra libraries like BLAS and LAPACK. Its used on super computers for massive Monte Carlo simulations for things like weather prediction. It comes with many unsung benefits:
It is an array language and supports vectorised operations out-of-the-box. It also supports a meddley of modern conveniences such as generic, derived types, operator overlading, templating, and so on.
It has exceptionally fast optimising compilers which produce native code. State-of-the-art compilers such as gfortran are open-source.
It tightly integrates with OpenMP for parallelism which is very easy to use both on a single machine and across machines. Newest versions support a native parallelism scheme called “coarrays”.
If you’re an experienced coder, Fortran is very easy to learn. I learned Fortran for the first time whilst doing these experiments. I would say its the easiest language I’ve ever learned.
For me it was between C++ and Fortran, and for the reasons above, I thought it would be more likely that I’d find other uses for Fortran in my line of work.
HARDWARE
All the timings were performed on my laptop: XPS13,
i7-1165G7 @ 2.80GHz, 16G RAM and SSD. The measurements.txt
file is about 15GB: it does not fit into RAM. Maximum disk
sequential read rate is fairly slow:
time cat measurements.txt > /dev/null
real 0m12.919s
user 0m0.004s
sys 0m4.653sI’m very reliant on disk cache for good results!
IMPLEMENTATION
Fortran doesn’t have a standard library and doesn’t come with very much out of the box beyond. I more or less have to build everything from scratch. This is what I have to conceptually achieve:
select station_name,
min(temp),
max(temp),
sum(temp)/count(*) as avg
from <measurements.txt>
group by station_nameIt was apparent to me that the algorithm needs to stream
the data from the 1B row measurements.txt file, and
continuously aggregate it into some structure. Any other
solution would involve processing the data more than once.
Since we are grouping by stations, using a hash table would
be the received wisdom, but I didn’t know much about the
alternatives so I decided to start by running some experiments
with other structures.
Commonalities
All experiments share a few common features:
Custom float parsing function arr2real which converts characters or integer(1) bytes into real. It is exceptionally quick because it exploits the known structure of the temperature readings. Namely that they must be in the range -99.9 to 99.9 and are always 1 dp.
Data is always processed sequentially in a single pass.
Note, I was/am learning more Fortran every day, so the code changes for the better in terms of structure and organisation as the experiments go on.
Exp. 1 (2m09s, 137LoC) : Left-child right-sibling
A Trie (prefix tree) is a simple way to encode a set of keys along with additional information about them. The diagram below (from Wikipedia) illustrates how it might be applied to counting words.
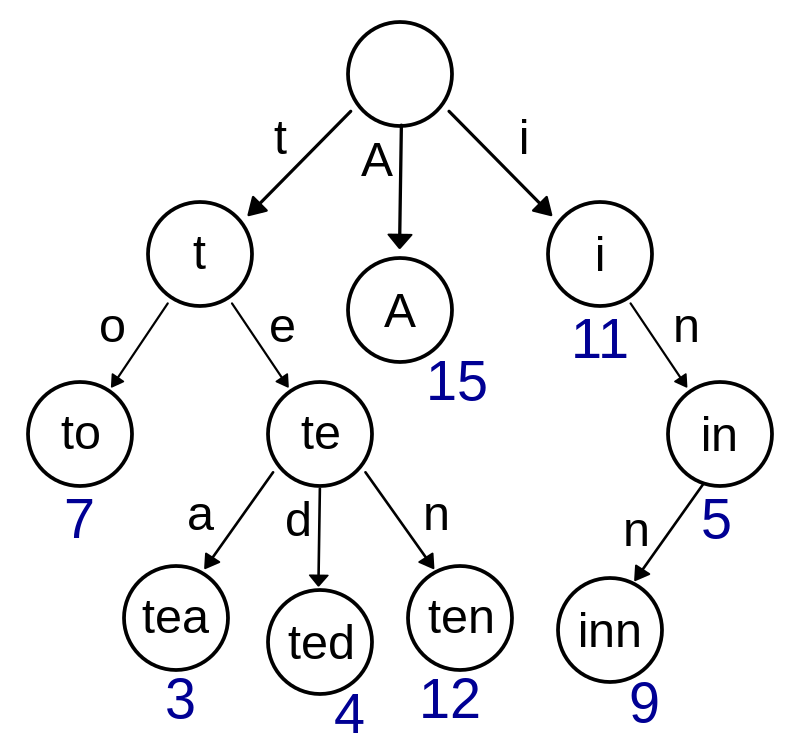 Insert or recovering information from the Trie has O(k) time complexity where k
is the length of the key, but in practice it can be fiddly to implement without
uncomfortable trade-offs.
Insert or recovering information from the Trie has O(k) time complexity where k
is the length of the key, but in practice it can be fiddly to implement without
uncomfortable trade-offs.
My first experiment centered on a binary version of a Trie known as left-child right-sibling (LCRS). The diagram below illustrates the concept. The tree on the left is a regular prefix tree, whilst the one on the right is a LCRS tree. The benefit of LCRS is that’s its more space efficient than a naive implementation, the drawback is that time complexity is no longer O(k) because finding adjacent nodes involves a linear scan.
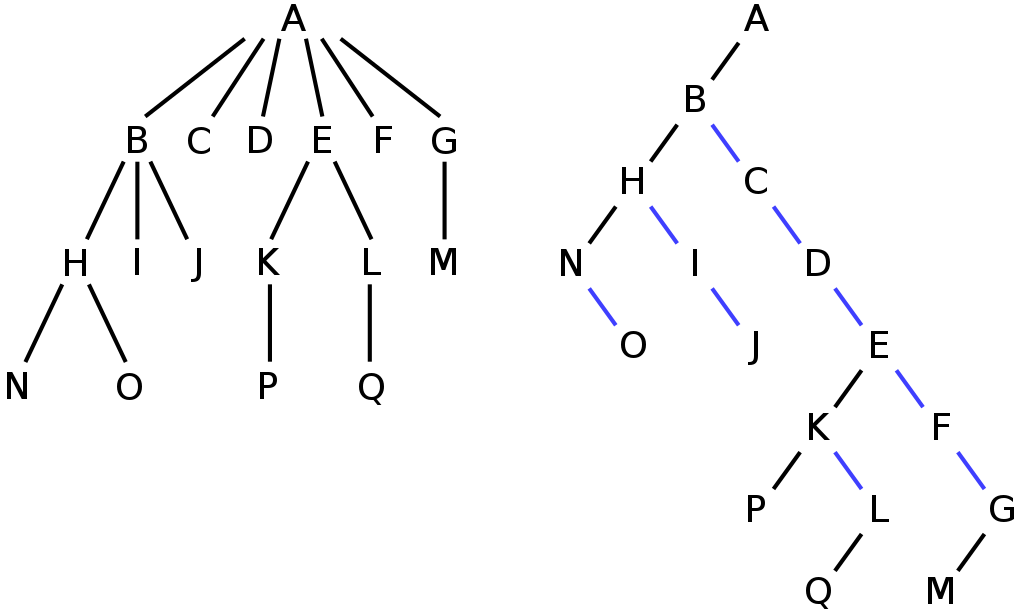 Nonetheless the program runs about 3 times faster than the AWK version and
established for me a benchmark to beat:
Nonetheless the program runs about 3 times faster than the AWK version and
established for me a benchmark to beat:
gfortran-13 -march=native -O3 -o 1brc 1brc_lcrs.f90
time ./1brc | wc -l
8875
real 2m8.789s
user 2m4.470s
sys 0m4.247sExp. 2 (1m25s, 118LoC) : Trie (vectors of pointers)
My second attempt was centered on a naive Trie implementation where instead of scanning for siblings, I store each possible character in an array of pointers. As a result the tree can be updated in O(k) time but at the cost of significantly higher space complexity. The diagram below (from Wikipedia) illustrates the situation:
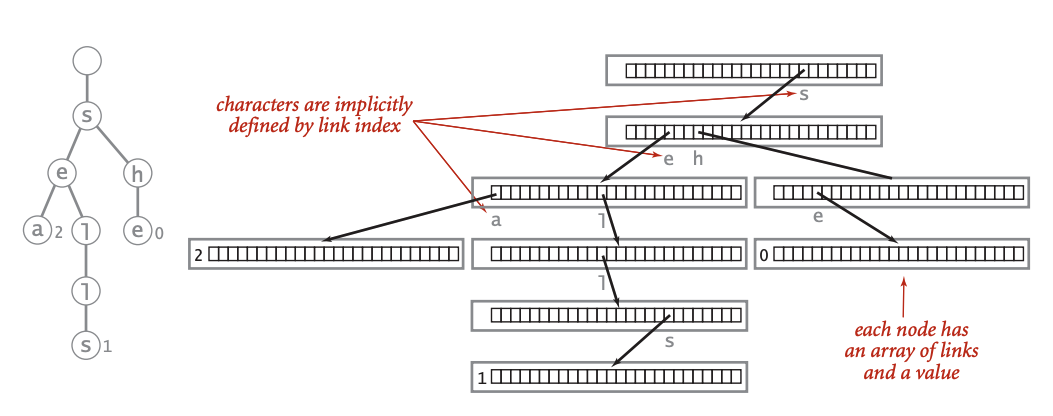 Each pointer vector is sparsely populated and has a length of 256 (one slot
for each possible character). Empirically speaking, I did not encounter memory
related issues, but it made a big difference to the speed of the algorithm:
Each pointer vector is sparsely populated and has a length of 256 (one slot
for each possible character). Empirically speaking, I did not encounter memory
related issues, but it made a big difference to the speed of the algorithm:
gfortran-13 -march=native -O3 -o 1brc 1brc_trie.f90
time ./1brc | wc -l
8875
real 1m25.561s
user 1m21.932s
sys 0m3.638sExp. 3 (0m44s, 138LoC) : Hash-table
A hash-table is (1) an array, (2) a hash function, and (3) a collision resolution strategy. Its job is to place an item in an array so that it can be retrieved in the fewest operations possible. I fixed the array size to 65536 because its a power of two (which enables me to use bit-wise operations instead of modulus when limiting the hash to the slots in the array), I used FNV-1a hash function (its fast and easy to implement) and I used linear probing to resolve collisions.
The difference in performance is massive. Clearly k lookups (Trie) is much slower than computing the hash, even if it requires many more than k operations and there is re-hashing involved.
gfortran-13 -march=native -ffast-math -O3 -o 1brc \
1brc_hash.f90
time ./1brc | wc -l
8875
real 0m43.873s
user 0m39.283s
sys 0m4.521sExp. 4 (0m30s, 148LoC) : Hash-table + mmap
In this experiment the big difference is using mmap to read the file via memory which moreso subjects it to system paging and caching. I moved to working with bytes instead of characters. I changed the hash implementation, optimised how record breaking works, and many other smaller changes. The performance improved considerably.
gfortran-13 -march=native -ffast-math -O3 -o 1brc \
1brc_hash_mmap.f90
time ./1brc | wc -l
8875
real 0m30.414s
user 0m28.744s
sys 0m1.037sExp. 5 (0m09s, 174LoC) : Hash-table + MMAP + OpenMP
The problem is “embarrassingly parallel” so I just chunk the input into some number of parts and then use OpenMP to implement a parallel do loop. I obtained the best results with 8 threads. I suspect this is because my machine has 4 cores each with 2 hyper-threads. The performance is roughly what I would expect given linear scaling: 30s / 4 ~ 8s, although IO becomes a significant bottleneck, and scaling the results to 8 cores would require high performance RAM and enough of it to cache the whole file.
gfortran-13 -fopenmp -march=native -ffast-math -O3 \
-o 1brc 1brc_hash_mmap_openmp.f90
time ./1brc | wc -l
8875
real 0m8.730s
user 1m4.247s
sys 0m1.391sCONCLUSIONS
It turns out that in 174 lines of Fortran code, we can write a high performance parallel implementation of a group by query. Here is a summary of the most important considerations:
- Do not process anything twice.
- Use a hash map with a fast hashing algorithm.
- Use mmap to improve read speed.
- Use all available cores (OpenMP).